负环判定
- $\textrm{Floyd}$:每进行一轮转移,我们检查所有 $\texttt{dis[i,i]}$ 是否小于 $0$。若小于 $0$ 则说明存在经过该点的负环。
- $\textrm{Bellman Ford}$:进行 $(n-1)$ 轮转移后再进行新一轮松弛,若还可以松弛就说明存在负环。因为一轮松弛相当于将最短路径伸长了一条边,而事实上并没有点数超过 $n$ 的简单路径。
- $\textrm{SPFA}$:
- 若一个点被 入队 $(n-1)$ 次,则说明存在经过该点的负环。注意不是判断被松弛 $(n-1)$ 次,这个可以结合 $\textrm{Bellman Ford}$ 算法理解,两次连续对同一个点的松弛 也可能在同一层的松弛中,即路径的长度并没有伸长,而只是换成了另一个松弛点而已。
- 考虑维护每个点当前最短路的路径长度(记为 $\texttt{cnt[i]}$)一开始除起点 $\texttt{cnt[S] = 0}$ 外,其他全部设为 $\texttt{cnt[i] = INF}$。当 $u \to v$ 松弛成功时,我们令 $\texttt{cnt[v] = cnt[u] + 1}$,同时判断 $\texttt{cnt[v]}$ 是否大于 $(n-1)$,如果是则找到了负环。这种方法比较严谨,速度通常也比较快。
最小环
- $\textrm{Floyd}$:注意到在第 $i$ 轮转移前,$\texttt{dis[x,y]}$ 表示的是「$x$ 只经过 $[1,i)$ 中的点到达 $y$ 的最短路」,那么我们在此刻检查所有 $i$ 的入边和出边 $x \to i \to y\ (x<i,y<i)$,向答案贡献 $\texttt{w[x,i] + w[i,y] + dis[y,x]}$,就能找到最小环。
- 删边法:每次删去一条边 $\texttt{(u,v)}$,跑一次单源最短路,此时答案贡献为 $\texttt{w[u,v] + dis[v,u]}$。若使用堆优化 $\textrm{Dijkstra}$ 算法求解最短路则复杂度为 $O(m (n+m)\log(n+m))$.
- 删点法:每次枚举一个起点 $S\in [1,n]$,我们先把 $S$ 的出边 $\texttt{(S,v)}$ 全部先松弛好,然后令 $\texttt{dis[S] = INF}$,然后再跑一遍最短路,最后得到的 $\texttt{dis[S]}$ 即为经过点 $S$ 的最小环。若使用堆优化 $\textrm{Dijkstra}$ 算法求解最短路则复杂度为 $O(n (n+m)\log(n+m))$。注意这种算法不能「直接」求解存在二元环的有向图或者无向图的最小环。(大概需要一些特判或者钦定法?)
欧拉路径 / 回路
- 欧拉路径:经过图上所有边 恰好一次 的路径。
- 欧拉回路:经过图上所有边恰好一次的 回路(起点和终点刚好一次的路径)。
判定:
- 有向图欧拉路径:图中 恰好 存在一个点使得其出度比入度多 $1$(这个点为起点),另一个点入度比出度多 $1$(这个点为终点),其余节点出度 $=$ 入度。
- 有向图欧拉回路:所有点出度 $=$ 入度。
- 无向图欧拉路径:图中 恰好 存在两点使得其度数为奇数(这两个点为起点&终点),其余节点度数为偶数。
- 无向图欧拉回路:所有点的度数均为偶数。
如何寻找:
- 欧拉回路:可以直接胡乱搜索找到,有边就走。这样有可能导致一个点有多个出边,但是这就说明这个点是个割点,又因为存在欧拉回路,因此每个出边走出去之后必然会有回来的边。因此可以直接拼接起来。
- 欧拉路径:一个节点多个出边时,不一定会有边回来了,但一定是最后一次的出边,因此我们可以用一个栈,每次在回溯的时候将这个节点放进去即可。最后按栈倒序输出。
- 无向图和有向图的找法是一样的,只不过不能走回父边。
算法的正确性可以使用归纳法证明,删去对应的一条边之后仍然满足判定条件,因此这是正确的。
时间复杂度 $O(n+m)$。
注意在 $\text{dfs}$ 的时候枚举边集时每经过一条边就要把这一条边从边集中删去,否则时间复杂度会退化为 $O(nm)$。
一个推论:图上欧拉路径最小划分数
- 无向图能划分为若干条欧拉路径,当且仅当 若奇度点的个数为偶数。
- 有向图能划分为若干条欧拉路径,当且仅当 若 「出度比入度多 $\textbf{1}$」 的点数与 「入度比出度多 $\textbf{1}$」 的点数相等,且其他点的出入度相等。
- 若满足以上条件,无向图 / 有向图的最小划分数均为 奇度点的个数除以 $\textbf{2}$ 。
欧拉回路计数:有向图欧拉回路计数参见 $\textbf{BEST 定理}$,无向图欧拉回路计数是 $\texttt{#P(Sharp P)-Complete}$ 问题。(据说比 $\texttt{NP}$ 问题还要难)
割点、点双连通分量与圆方树
下面均为在 无向图 上讨论以上元素。
注意:无向图上 DFS 时只有树边和返祖边。
- 割点:用 Tarjan 来求,充要条件:
- 存在出点 $v$ 使得 $\texttt{low[v]>=dfn[u]}$。
- 起始点的判定方式不同:直接判断 DFS 树上有多个出边即可。
- 判断点双连通:
- 充要条件:DFS 树上两点路径没有割点。
- 找点双连通分量:
- 性质:割点至少属于一个点双,非割点属于且仅属于一个点双。
- 使用 Tarjan 算法。每当发现有 $\texttt{low[v]>=dfn[u]}$,此时 $u$ 是割点,栈顶至 $v$ 的所有元素 与 $u$ 本身 形成了一个点双连通分量。将它们从栈中弹出即可。
- 构建圆方树:
- 圆方树中,圆点表示原图上的节点,方点表示一个强连通分量。
- 圆方树上只有圆方边,也就是说圆点和方点是交替连接的。一条圆方边表示方点对应的点双 包含 原点对应的节点。 - 度数为 $1$ 的圆点均为非割点,度数 $>1$ 的圆点均为割点。
- 使用 Tarjan 算法构建:每当发现有 $\texttt{low[v]>=dfn[u]}$,栈顶至 $v$ 的所有元素 与 $u$ 本身 形成了一个点双连通分量。因此我们新建一个方点,将刚才的所有节点都连向它即可。
桥与边双连通分量
- 桥:
- 先建出 DFS 树。非树边都不是桥。非树边端点的两点路径上的边都不是桥。其他都是桥。
- 用 Tarjan 来求。充要条件 $\texttt{low[v]>dfn[u]}$。不用特判起始点。
- 判断边双连通:
- 充要条件 DFS 树上两点路径上没有桥。
- 找边双连通分量:
- 性质:每个点属于且仅属于一个边双连通分量。
- 使用 Tarjan 算法:此时每次递归需要记录 DFS 上的出边是哪一条,往下递归时不能走回父亲。然后在回溯前判断一下是否 $\texttt{low[x]=dfs[x]}$,如果是,那么就是说该节点是它所在边双在 DFS 树上的最浅点。此时栈中到 $x$ 的所有元素 形成了一个边双连通分量。
2-SAT
有 $n$ 个元素,每个元素有 $2$ 种状态 $(0/1)$。
现在给出 $m$ 个限制 $(a_i,b_i,w_i,v_i)$:若第 $a_i$ 个元素为 $w_i$,则第 $b_i$ 个元素必须为 $v_i$。
问是否有合法方案,并给出构造。
我们将每个元素分成 $x_{i,0},x_{i,1}$ 两个点,考虑往里面连边。那么对于一个限制 $(a_i,b_i,w_i,v_i)$,则:
- $x_{a_i,w_i}$ 向 $x_{b_i,v_i}$ 连一条有向边:表示若 $x_{a_i,w_i}$ 成立则 $x_{b_i,v_i}$ 也成立。
- $x_{b_i,\neg v_i}$ 向 $x_{a_i,\neg w_i}$ 连一条有向边:表示 逆否命题,这样才能完整叙述这个限制。
然后我们跑 $\texttt{Tarjan}$,此时所有的强连通分量均表示「若有一状态成立则所有状态均成立」。
- 不合法的判定:判断是否有存在一个元素 $i$,使得 $x_{i,0}$ 与 $x_{i,1}$ 在同一个强连通分量里。
- 构造方案:对于 $x_{i,0}$ 与 $x_{i,1}$,我们判断两个状态在缩点后的 $\textrm{DFS}$ 序 哪一个更大,我们选取较大者的状态即可。因为这样就可以避免较小的状态可以导致较大的状态也成立。
时间复杂度 $O(n+m)$.
这个算法只能够用作 判定 和 构造特解。而无法构造出所有合法方案。
- $\texttt{k-SAT}$:此时每个元素均存在 $k(k>2)$ 个状态。这个问题是 NPC 问题。
Hall 定理
- Hall 定理:对于一个二分图 $\langle V_1,V_2,E\rangle,|V_1| \le |V_2|$,那么 该二分图存在完美匹配的 充分必要条件 是:对于 $\forall S \subseteq V_1$,记邻域集合 $N(S) = {y | \exists (x,y)\in E, x\in S,y\in V_2 }$,则有 $|S| \le |N(S)|$。
这个充要条件简单来说,就是如果在二分图上左部点的任意一个子集,它所有连向右部点的集合(邻域)大小,总是比该子集要大。
证明:
- 必要性:假设存在完美匹配而不满足该条件。
那么我们能找到一个子集,它的邻域比它小,那肯定会有左部点无法匹配。显然矛盾。
- 充分性:假设满足该条件而无完美匹配。
我们使用类似匈牙利算法的思想,重复以下步骤:
- 找到左部点还未匹配的点,并找到它连向的右部点;
- 将这两点匹配,并找到因此失配的左部点。
以此类推就能找到一条增广路。因为这张图满足 Hall 定理,所以总能找到右部点,因此可以一直增广,直到找到完美匹配。
这个定理也可以适用于二分图带权完美匹配的判定。
- Hall 定理推论:若左部点每个点的度数均 $\ge k$,而右部点每个点的度数均 $\le k$,那么这个二分图存在完美匹配。
考虑反证法。假设存在左部点的一个子集 $S$,使得 $|S| > |N(S)|$,那么右部点的度数总和
$$\sum_{i\in N(S)} \deg(i)< k·|N(S)| < k·|S| \le \sum_{i\in S} \deg(i)$$
明明向邻域连了 $\sum\limits_{i\in S} \deg(i)$ 条边,而邻域的度数总和居然严格小于这个总边数。故假设矛盾,因此原命题正确。
虽然这个推论好像有点反直觉。(仅凭度数大小就能判断是否存在完美匹配)
我们称所有点的度数均为 $k$ 的二分图为 $\bf k-$正则二分图,那么由这个推论可知 $\rm k-$正则二分图 必然存在完美匹配。
二分图最大匹配
匈牙利算法
考虑每次新加入一个左部点,不断调整匹配。我们沿着左部点的每条边找右部点:
- 如果右部点还未匹配:匹配成功;
- 如果右部点已经匹配:我们先将这个点与右部点匹配,然后把原来匹配的点重新寻找匹配点,递归求解即可。
- 如果递归到某一层发现访问到了原来的点,则这个点失配。
每次暴力调整时我们最多把每个右部点访问一次,故总时间复杂度为 $O(nm)$。
代码量很小。而且时间复杂度经常跑不满。
通过这个算法我们可以很容易得到一组方案。
网络流
新建超级源点和超级汇点。
- 超级源点 $\to$ 各个左部点,容量为 $1$;
- 左部点 $\to$ 右部点:由题目给出的边,容量为 $1$;
- 各个右部点 $\to$ 超级汇点,容量为 $1$。
正确性,显然。一组匹配相当于 $1$ 个单位的水。时间复杂度已被证明为 $O(m\sqrt n)$ (证明)。
代码量中等,但是时间复杂度优秀,并且可以有很多拓展(可以给边加上其他信息)。
二分图带权最大匹配:KM 算法
对于这个我没有什么很好的理解,只能跟着题解的思路走…..
首先将原问题转化为二分图带权「完美匹配」问题:
- 如果左右部点数目不相等,那么我们在数目少的一侧新增若干个虚点,使得两边相等;
- 我们视作任意两个左右部点之间都有一条边。只是如果一开始不存在的话,则边权为 $0$;
则此时这个图必有完美匹配。
给每个点定义一个权值,该算法称这个权值为「顶标」。我们记点 $i$ 的顶标为 $l_i$。
对于一条边 $(x,y)$,需满足:$l_x+l_y-w(x,y)\ge 0$.
我们再新建一个子图。这个图由原图生成:若原图的一条边 $(x,y)$ 满足 $l_x+l_y-w(x,y)=0$,则将这条边加入这个子图中。
$\triangle$ 性质:若该子图存在完美匹配,则该完美匹配为原图的带权最大完美匹配。
证明:
- 原图的一个完美匹配权值总和为 $\sum w(x_i,y_i)\le \sum l_{x_i}+\sum l_{y_i}$
- 这个子图的完美匹配权值总和为 $\sum w(x_i,y_i)=\sum l_{x_i}+\sum l_{y_i}$。
故原图的任一完美匹配总是小于等于该子图的完美匹配。
现在问题转化为给这一系列「顶标」定权,使得子图存在完美匹配。
类似于匈牙利算法。考虑加入一个左部点 $x$,我们调整匹配和右部点的顶标。
我们需要求出所有 $x$ 与右部点的连边 的 $d=l_x+l_y-w(x,y)$ 最小值和具体对应的边。然后给所有已匹配的左部点 $-d$,右部点 $+d$。然后就能保证这条最小的边的 $d=0$,给这条边加入子图。
重复这样的过程,最后就能求出来了。
这样的时间复杂度是 $O(n^4)$ 的,可以使用:1.实时记录同一个右部点的 d 的最小值;2.匈牙利算法改成 bfs 形式。 优化到 $O(n^3)$。
KM 算法只能求解匹配问题。因为它只是一种大力强行调整匹配的算法……
事实上,二分图带权最大匹配也能用费用流做,建边与二分图最大匹配相似,只是增加了费用。
传递闭包
- 传递关系 $(i,j)$:$i$ 和 $j$ 之间有一条有向边 $i\to j$。
- 传递闭包问题:已知一张有向图(即给出了若干个传递关系)。现在需要你求出任意两点 $x,y$ 能否从 $x$ 走到 $y$。
使用类似 $\texttt{Floyd}$ 的算法实现即可。只不过矩阵里面的数变成了 $0/1$。
可以用 $\texttt{bitset}$ 优化。
如果不一定要把任意两点的答案求出来,则容易先缩点再拓扑排序求得答案。
差分约束
构造一组解使得方程组 $x_{p_i} - x_{q_i} \le d_i\ (i = 1, 2, \cdots n)$ 成立,或者说明无解。
这个很熟悉了。只列一下常见转化:
- $x_i-x_j\le d\Rightarrow x_i\le x_j+d$;
- $x_i-x_j\ge d\Rightarrow x_j\le x_i-d$;
- $x_i-x_j=d\Rightarrow x_i-x_j\le d ,x_i-x_j\ge d$.
由于这些变量整体加/减一个值没有影响,所以我们令某一个变量为 $0$,然后跑 SPFA(有负权边) 即可。
无解的条件是,存在负环。
同余最短路
- 完全背包,物体的重量很小,但是背包容量很大,问能不能拼出这个容量;
- 完全背包,拼出最小的模 $K$ 余 $p$ 的数;
具体操作是我们找到一个合适的数作为这个背包的「模数」$p$(可以选定一个物品的重量,也可能是题目给出的)。此时状态 $f(i)$ 表示「能拼出的重量 满足 $\bmod p=i$ 的最小重量」。
然后把物品视作一个个转移:$f((i+w)\bmod p)=f(i)+1$;
然后跑最短路即可。
但是这样转移有一定的局限性,每个状态要么记「最小的重量」却不知道这个重量是如何拼出来的,要么记「能拼到这个模数的最大价值」而不知道这个价值真正的重量是多少。它丢掉了一些信息,换来的是时间复杂度的改进。
最小斯坦纳树
给定的 $k\ (k \le 10)$ 个关键点,要求在原图上选一些边使这些关键点连通且代价之和最小。
如果没有关键点的限制,则退化为最小生成树问题。类比可以推出,最优方案必定也是一棵树。
$k$ 很小,考虑状压。设 $f(S,i)$ 为钦定 $i$ 为根,并且让关键点集合 $S$ 与 $i$ 联通的最小代价。对 $i$ 的度数考虑:
$i$ 的度数为 $1$:则 $f(S,i)=f(S,v)+w_{i\to v}$;
$i$ 的度数 $>1$,则 $f(S,i)=\min_{T\subset S} f(T,i)+f(\complement_S T,i)$
对于第一种情况,使用 $\texttt{Dijkstra}$ 对 $f(S,_)$ 进行最短路。
对于第二种情况,可以枚举子集。
注意我们要先处理第二种情况再处理第一种情况(原因:先继承前面的状态)。
注意按照 $|S|$ 升序枚举。
时间复杂度 $O(n·3^n+(n^2+m\log m)·2^n)$,若用堆优化则 $O(n·3^n+(n+m)\log m·2^n)$。但其实并没有必要。都能状压了, n^2 轻轻松松
同时我们注意到这是模板题却使用了指数级算法。维基百科告诉我们,普通的斯坦纳树问题是 $\texttt{NP-hard}$ 问题。
最小割树
给定一个无向图,有 $Q\ (Q\le 10^5)$ 次询问,多次求两点间最小割。
类似于最小生成树代替两点路径最小值一样,我们对于这个两点最小割也构造出一个「最小割树」。
构造方法:
- 选定两个点(随便选定),求出这两点在原图上的最小割。
- 对于我们在最小割树上连接这两个点,边权为最小割的值。
- 根据最小割的割边方案可以将点集分成两个互不相交的集合。
- 对于这两个集合继续递归求解。直到集合只剩一个元素为止。
.$\triangle$ 性质:两点在原图的最小割 $=$ 两点在最小割树的路径上边权最小值。
简略证明:
- 【引理】可行割 $\ge$ 最小割。(显然)
- 【证明上界】对于每次分割成的两个集合 $S_x,S_y$,$\forall p_0\in S_x,p_1\in S_y,Cut(x,y)\le Cut(p_0,p_1)$。显然 $p_0$ 到 $p_1$ 是 $x$ 到 $y$ 的最小割的一种可行割。因此路径上的最小值必然也 $\ge Cut(x,y)$。
- 【证明下界】$\forall z,Cut(x,y)\ge\min(Cut(x,z),Cut(z,y))$。因为 $x,y$ 的最小割中 $z$ 要么在 $x$ 一侧,要么在 $y$ 一侧,所以 $Cut(x,y)$ 必然是 $Cut(x,z),Cut(z,y)$ 之一的可行割。因此路径上的最小值必然也 $\le Cut(x,y)$。
因此 $Cut(x,y)=$ 最小割树路径最小值。
最坏时间复杂度 $O(n·\text{最大流复杂度})=O(n^3m)$。但很难达到该上界。
最小树形图
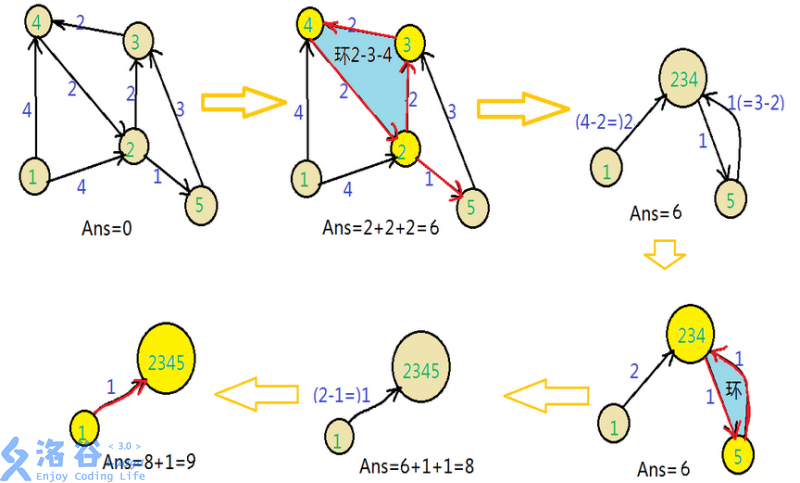
重复这样的过程:
对于(除了根的)每个点,我们找到每个点的入边中权值最小的边,并记下对应的出点,将边权累加到答案中。
- 如果找不到这样的 $n-1$ 条边,则无解。
- 如果这 $n-1$ 条边没有形成环,则直接输出答案;
- 否则,这些环必定为简单环(每个点入度只为 $1$),我们找出所有的环,然后将这些环缩起来。然后把每条边的边权减去被指向的点原先选择的边的边权。(意义:后面若选择这条边则将原来选择的边反悔)
由于这里只有简单环,所以我们不需要用 $\texttt{Tarjan}$ 缩点,只需一步步往前跳,若跳到前面跳过的点则停止即可。
网络流技巧
有了 dinic,就有了全 世 界!
好文章:click / click / click / click
- 如何使最大流的 Dinic 算法达到理论上的最坏时间复杂度? - 知乎
- Dinic 算法已被证明复杂度为 $O(n^2m)$,但很多时候甚至可以把它当作 $O(n+m)$ 的复杂度。
- EK 算法可以被卡到指数级复杂度。但很多时候图是我们自己建的,所以据实战经验来说,运行效率也十分优秀。
网络流相当于给予了你一个可以进行最优决策的自动机。因此衍生出了许多问题。
咕咕咕 只会一些简单的
杂项
- 【最小割】若选 $i$ 则必须选 $j$:则 $i\to j$,边权为 $+\infty$。这样可以强制两个点联通。
- 【最大流/费用流】结点有流量限制,即限定经过/选择点 $i$ 至多 $k$ 次:将 $i$ 拆成两个点 $in(i)$ 和 $out(i)$。作为入度点时连向 $in(i)$,作为出度点时从 $out(i)$ 连出。然后 $in(i)\to out(i)$,权值为 $k$。
- 【最大流/费用流】选择一段特定的区间:我们先每个点往后连边 $i\to i+1$。然后对于区间 $(l,r)$,我们直接连接端点 $l\to r$,剩下的限制在这条边的 容量/费用 上做文章。
输出方案
虽然这不是建图技巧,但我没位置放了
最大流方案:无脑输出流量。
最小割方案:由于我们跑的是最大流,所以在最后一次 bfs 的时候,残量网络中 $S$ 和 $T$ 必定不连通。并且我们在 bfs 时,所有能被分到层的都是与 $S$ 联通的。所以我们输出这些有层数的点和没层数的点之间的边即可。
最小割的可行边和必须边
显然 ${\text{必须边}}\subseteq{\text{可行边}}$.
可行边的充要条件:
- 在任意一种方案中满流(瓶颈边)。否则,必定会有更小的、限制其流量的边作为割边。我们可以先找到一种方案中满流的边,然后再进行下述判断。
- 将残量网络(只考虑有残余流量的边)缩点之后,这条边的两个端点不在同一个强连通分量当中。否则,我们找到强连通分量中包含这一条边的环,然后将流量沿着这条流量来流,这样就能构造一种方案使得这一条边不满流。
必须边的充要条件:
- 在任意一种方案中满流。(同上)
- 设这条边为 $(u,v)$,那么 $S$ 能(沿着残量网络非0边)走到 $u$,而 $v$ 能(沿着残量网络非0边)走到 $T$。这样我们就找到了一条包含 $(u,v)$ 的路径,使得它为这一条路径的瓶颈,且瓶颈上的边都大于它。
二分图匹配:超级源点和超级汇点
S - x[i]:边权为 $1$;x[i] - y[j]:边权为 $1$,前提是这两个点有边;y[j] - T:边权为 $1$。
已被严格证明时间复杂度为 $O(m\sqrt n)$。
最大权闭合图($01$ 最小割):「选择负权边 $\to$ 舍弃正权边」的转化
一个非常经典的模型,可以解决许多「二元对立」的最优化问题。
有 $n$ 个点,每一个点可以选或者不选。
一个点选了或者不选,要付出一定的代价或者得到一定的收益(或者说收益有正有负)。
有一些点之间有特定的关系。求最后的收益/代价最大或者最小。
- $S\to p_i$:权值为 $p_i$ 的收益大小(正数的收益);
- $p_i\to p_j$:这里描述为「若选择 $i$ 则必须选择 $j$」,权值为 $+\infty$;(注意连边方向不要反了)
- $p_i\to T$:权值为 $p_i$ 的费用大小(负数的收益);
注意这里权值都是正的。
对它求一个最小割,答案为「(正数的)收益总和 - 最小割」。
它的意义是:
- 割去(正数)收益的边:舍弃了这个收益;
- 割去(负数)收益的边,承担了这个代价。
让「承担的代价 + 舍弃的利益」最小,因此用最小割是正确的。
距离限制模型(切糕模型)
有 $n$ 个元素,每个元素可以选择 $[1,k]$ 中的数,每个数有一定的收益。
限制:规定元素 $p_i,\ q_i$ 选择的数之差不超过 $D$.
求合法的最大收益。
- 连 $n$ 条这样的链:$S\to 1\to 2\to\dots\to k\to T$:代表一种元素的选择,边权为每个数的收益。当我割掉一条边就说明该元素选择了这个数(并获得该收益)。
- 对于限制中的 $p_i,q_i$:将所有的 $(p_i,x+d)\to(q_i,x)$ 和 $(q_i,x+d)\to(p_i,x)$ 连一条权值为 $+\infty$ 的边。意义:当这两个元素割掉了了差值大于 $d$ 的边,那么这里面就会有一条边使这两条链把 $S,T$ 联通。
{kind=link}
对它求一个最小割即可。
网络流相关 图论经典模型
$\textbf{DAG}$ 上最小不相交路径覆盖
- 给定一个 $\text{DAG}$,找出最少的路径数,使得任何一个顶点仅在这些路径中的 恰好 一条路径中出现。
结论:
$$\textbf{最小不相交路径覆盖数 = 顶点数 - 最大匹配数}$$
假设我们一开始没有任何的边,每一条路径只包含一个点。如果给其中两个路径的首末连一条边,那么这两条路径就会发生合并。也就是说,这个时候路径数就减少了 $1$。
如果我们把最大匹配的每组点的首末都连起来,那么路径覆盖数就是最少的。
因为每个点会指向某一个点,也有可能被某一个点指向。因此我们应该将一条边拆成两个点 $in(i),out(i)$:
- $S\to out(i)$:边权为 $1$;
- $out(i)\to in(j)$:边权为 $1$,前提是这两个点有边;
- $in(i)\to T$:边权为 $1$。
跑一个最大流即可。
如果使用匈牙利算法,在实现过程中可以不用拆点,还可以很容易得到一组方案,我们将匹配当做一条边即可。
- 根据维基的说法,一般图 的最小不相交路径覆盖,求解难度不亚于「哈密顿回路问题」,是一个 $\texttt{NP-hard}$ 问题。
$\textbf{DAG}$ 上最小可相交路径覆盖
- 给定一个 $\text{DAG}$,找出最少的路径数,使得任何一个顶点仅在这些路径中的 至少 一条路径中出现。
我们对原图先用 $\texttt{Floyd}$ 求一个传递闭包。这样转化后,两点有边相连只说明 两点存在路径。所以这个图的一条路径等价于原图的一条路径,但只是选择了这条路径上的若干个点。
如果我们对这个图求 最小不相交路径覆盖,如果两个原图上的路径相交,在新图上我们可以令其「越过」相交的点,这样就可以考虑到了相交路径了。
二分图最小点覆盖
在二分图上,选出最小的点集,使得每条边都 至少有一个端点 被选择。
$$\textbf{König 定理:二分图上最小点覆盖数 = 最大匹配数}$$
如何构造方案:假设我们已经通过匈牙利算法求出了最大匹配。现在我们执行下列操作:
- 依次从各个 尚未匹配 的左部点开始,继续像匈牙利算法那样寻找增广路。显然由于我们已经找到了最大匹配,所以增广操作一定不会成功。
- 在寻找的过程中,我们给所有访问到的点打上标记。
- 未被标记的左部点 和 被标记的右部点 组成了最小点覆盖集。
我们梳理一下这个被标记的二分图的性质:
未被匹配的左部点和右部点 一定不存在边相连。
否则匹配数还能增加。因此未匹配左(右)部点的边一定连向已匹配的右(左)部点。
不可能存在一条边使得 左端点被标记,右端点未被标记。
否则在遍历这个左端点的时候,我们就会成功找到一条增广路。根据这个性质,我们便可以证明选出的点集可以覆盖所有的点。
未被匹配的左部点 一定被标记。
因为它们一定会被作为寻找增广路的起点被标记。因此它们不会被纳入选出的点集中。
未被匹配的右部点及与其相连的左端点 一定不会被标记。
因为和它相连的左端点一定是匹配点。若左端点被标记,那么就会顺理成章地访问到这个右部点,从而找到增广路。因此这两个端点都不会被标记。因此它们也不会被纳入选出的点集中。
对于一条匹配边,要么都未被标记,要么都被标记。
因为不可能右端点被标记而左端点未被标记,否则右端点可以通过这条匹配边访问到左端点。再根据性质 2.,我们可以总结出该性质。因此每一条匹配边均会恰有一个端点纳入选出的点集中。
根据性质 3~5,这个选出的点集的大小即为最大匹配数。
最大匹配数为最小点覆盖集的下界。
这是显然的。因为对于每个匹配至少都要选择一个点才能覆盖这一条边。
根据以上性质,我们证明了该点集为合法点覆盖集且为最大匹配数,并证明了最大匹配数为最小点覆盖的下界。因此该点集为最小点覆盖集。同时顺便证明了 $\textbf{König 定理}$。
二分图最大独立集
- 在二分图上,选出最大的点集,使得这些点不存在边相连。
结论:
$$\textbf{最大独立集 = 顶点数 - 最小点覆盖}$$
因为如果我们将最小点覆盖的点去掉,那么剩下的每条边均只剩下一个端点,因此这一定是独立集(定义)。又因为最小点覆盖是点数最小的,因此最小点覆盖的 补集是最大独立集。
即在做完上面求最大匹配 + 增广标记之后,被标记的左部点 和 未被标记的右部点 组成了最大独立集。
一般图 的最大匹配、最小点覆盖、最大独立集都是 $\texttt{NP-hard}$ 问题。
Dilworth 定理
一些定义:
- 偏序集:本质上是一个 DAG。有向无环图上的一个节点表示一个元素,一条边 $(u,v)$ 表示大小关系:$u\le v$。偏序集满足三个条件:
- 自反性:$\forall a\in S,a\le a$;
- 对称性:$\forall a,b\in S$,若 $a\le b$,则 $b\ge a$;
- 传递性:$\forall a,b,c\in S$,若 $a\le b,b\le c$,则有 $a\le c$。
- 链:在偏序集中的一个子集,如果这个子集内的元素是两两可比的,那么我们称这个子集是偏序集的一条链。在 DAG 上表示为就是一条链。
- 反链:与「链」的定义相对。它也是偏序集上的一个子集,如果这个子集内的元素是 两两不可比 的,那么我们称这个子集是偏序集的一条反链。在 DAG 上表示为这些点没有边相连,即一个 独立集。
- 最长反链:即 DAG 上的 最大独立集。我们在偏序集上能找到最大的反链。
- 最小链 / 反链划分:将偏序集划分为若干个集合,使得这若干个集合均为链 / 反链。求最小的集合。
狄尔沃斯定理(Dilworth’s theorem) :亦称偏序集分解定理。
- 对于任意有限偏序集(DAG),其
$$\textbf{最长反链长度 = 最小可相交链划分数}$$
构造方案:如果我们若想要求一个 DAG 的最长反链,那么我们先求传递闭包,然后拆点求最大独立集,那么最长反链即为最大独立集 左右部点之交。
构造方案正确性证明:显然这个构造出的反链是合法的,现在我们需要证明这个反链是最长的。由上面的构造过程有
- $\text{最大独立集} = 2n - \text{最小点覆盖}(m)$.
- $\text{最大独立集} - \text{构造反链} = \text{左右部点其一在最大独立集的个数}(\le n)$.
- 由上面两式得:$(2n-m)-\text{构造反链} \le n$,即 $\text{构造反链} \ge n-m$.
- 又由 $\text{最长反链} \le \text{最小可相交链划分数} = n-m$,因此 $\text{构造反链} = n-m$.
因此我们证明了构造出的反链为 最长反链。
- 其对偶定理:对于任意有限偏序集(DAG),其
$$\textbf{最长链长度 = 最小反链划分数}$$
常作第一步转化用。
有上下界的网络流
无源汇上下界可行流
由于每条边现在的流量限制从 $[0,r_i]$ 变成了 $[l_i,r_i]$,所以我们先钦定每条边的初始流量为 $l_i$,而这条边可调控的限制变成了 $[0,r_i-l_i]$。
对于每个点,我们算出流入这个点和流出这个点的初始流量 $in(i),out(i)$。
- $in(i)>out(i)$:等价于这个点凭空流入了一些水,我们连边 $S\to i$,流量为 $in(i)-out(i)$。
- $in(i)=out(i)$:我们不做任何操作;
- $in(i)<out(i)$:等价于这个点凭空流出了一些水,我们连边 $i\to T$,流量为 $out(i)-in(i)$。
然后对于每个原来的边我们照样连 $u_i\to v_i$,只不过流量变成了 $r_i-l_i$。
最后跑一次最大流即可。合法的条件是每一条 $S\to i$ 和 $i\to T$ 的边都是满流的。(因为本来我们就是假定了这些边满流)
有源汇上下界可行流
现在出现了源点和汇点。此时容易发现,若我们按照无源汇的方法去连之后,只有源点和汇点不满足流量守恒。
所以我们增加一条 $T\to S$,流量为 $[0,+\infty]$。这样整个系统又能转起来了。
注意无源汇的 $S/T$ 与这里的源汇点是不一样的。需要新建一个 $SS/TT$ 作为真正的超级源汇点。
有源汇上下界最大流
我们按照上面的做法,可以得到可行流。现在我们需要得到最大流。
我们删除超级源点和超级汇点和新增的 $T\to S$ 边。在残量网络再跑一次 $S\rightsquigarrow T$ 的最大流即可。
事实上,我们只需要删除 $T\to S$ 边,因为存在可行流亦可以说明与超级源汇点相连的边都是满流的,相当于不存在。
有源汇上下界最小流
最大流的思想是:我们先求出可行流,然后考虑在这个可行流上调整。事实上最小流也是这样的思想。
我们删除(超级源点和超级汇点和)新增的 $T\to S$ 边。在残余网络再跑一次 $T\rightsquigarrow S$ 的最大流即可。(意义理解:反悔流)
答案为:可行流 $-$ $T\rightsquigarrow S$ 的最大流。
有源汇上下界最小费用 可行流/最大流/最小流
给边权增加费用的信息即可。
以上,我们将上下界网络流转化为了普通网络流问题。因此上下界网络流的时间复杂度均与普通网络流的复杂度一致。
实战时,(先考虑)普通网络流建模 $\rightarrow$ (不行再)上下界网络流建模 $\rightarrow$ (最后再)费用流建模
模拟费用流
无向图三元环 / 四元环计数
给定一张无向图,求出 (a,b,c) 的无序对数使得它们两两有边。
给定一张无向图,求出 (a,b,c,d) 的无序环数使得它们相邻两两有边。
考虑给所有的边定向。对于一条边:
- 若两个端点的度数不相等,则度数较小的点连向度数较大的点;
- 若两个端点的度数相等,由编号较小的点连向编号较大的点。
不难发现这样的图是 DAG。注意到原图中:
- 三元环成了 $a\to b,b\to c,a\to c$。
- 四元环成了 $a\to b,a\to c,b\to d,c\to d$.
对于三元环,我们枚举 $x$ 的邻接点 $y$,再枚举 $y$ 的邻接点 $z$,然后 $z$ 是否为 $x$ 的邻接点。如何快速判断一个点是另一个点的邻接点?对于每个 $x$,我们先把所有 $x$ 的邻接点先用个数组打个标记,然后就能快速判断了。
对于四元环也类似,我们主要计算 $x$ 有多少不同的「只走两步」的方式可以到达 $z$,我们每次将 $y$ 的邻接点 $z$ 处的操作改打标记为 记录标记次数,这样就可以统计出来每个 $z$ 的标记次数 $cnt_z$。最后直接计算 $\sum \binom{cnt_z}{2}$.
这个算法的时间复杂度是 $O(m \sqrt m)$。(注意只与边数 $m$ 相关)。
- 当 $x$ 的度数小于 $\sqrt m$ 时,那么每次它只会访问至多 $\sqrt m$ 个点;
- 当 $x$ 的度数大于 $\sqrt m$ 时,由于我们是度数小的连向度数大的,所以最多连向 $m/\sqrt m=\sqrt m$ 个点,因此也至多访问 $\sqrt m$ 个点。
在每轮的 $x$ 访问它的每个邻接点的时候,我们扫描了一遍这个邻接点的邻接点集合。所以每一条边的贡献为 $O(\sqrt m)$。故总时间复杂度为 $O(m\sqrt m)$。
因此,我们通过这个算法可以得出一个小小的结论:一个图中三元环的数量上界为 $m\sqrt m$(注意是边数),至于与点数有关的就是 $O(n^3)$ 了。
Kruskal 重构树
定义:我们将 Kruskal 每次连边的时候,新建一个虚点连向这两个集合作为它们的父亲,定义父亲的权值为加入的这条边的权值。最后得到一个 $(2n-1)$ 个节点的新树。
性质(这里只讨论边权总和最小的 Kruskal 生成树):
- 重构树是大根堆,且原图上的节点等价于重构树上的叶子。
- 重构树上两点 lca 为两点路径最大值的最小值(最小瓶颈生成树);
- 原图上一个点经过不超过 $x$ 的边能走到的点,等价于重构树这个点经过权值不超过 $x$ 能走到的点。由于它是小根堆,所以可以倍增往上爬找到一个最大的子树。(由从小到大加边得到这个性质)
- 一个图所有的最小生成树只考虑它的边权排序后形成的序列完全相同,并且在所有的生成树中字典序最小(注意是给边权排序后再比较)。
- 将一个图上的所有边分成若干组,我们对这若干组各自求 MST,然后将每组内 MST 选择的边放在一起,再求一次 MST。则这个最小生成树为 原图 的最小生成树。这个结论在求完全图的 MST 的时候很有用,我们可以将边恰当分层以去掉一些无用的边。