A video can be seen as 2D image + time.

If an image is a tensor of shape $3 \times H \times W$, then a video clip is a tensor of shape $$ T \times 3 \times H \times W $$ or equivalently $$ 3 \times T \times H \times W. $$
For image classification, we usually recognize objects / scenes. For video understanding, we often want to recognize actions.
Examples:
- image: dog, cat, truck
- video: running, swimming, jumping
A practical problem is that videos are huge.
- videos are often around $30$ fps
- uncompressed video is very expensive to store and process
- therefore we usually train on short clips with lower fps and lower spatial resolution

A standard recipe:
- during training, sample short clips from long videos
- during test time, run the model on several clips and average predictions
High-level idea: for video classification, we rarely process the whole raw video directly. We usually process a manageable clip and then aggregate across clips.
Temporal modeling with CNNs
Single-frame CNN
The simplest baseline is:
- treat each video frame as an image
- run a standard 2D CNN on each frame independently
- average the predicted probabilities over frames
This is surprisingly strong.
The understanding of single-frame CNN:
- many action classes can already be guessed from appearance alone
- some datasets contain strong scene / object bias
- therefore this baseline should always be tried first
But it does not explicitly model motion.
Late fusion
A slightly stronger idea:
- run a 2D CNN on each frame
- extract frame-level features
- combine them only at the end
Two common ways:
- Late fusion with FC layers
- get feature maps for all frames
- flatten / concatenate them
- feed them into an MLP
- Late fusion with pooling
- get feature maps for all frames
- average pool over space and time
- feed the pooled feature into a linear classifier
Intuition:
- first get high-level appearance features for every frame
- then combine them across time
Problem:
- temporal interaction happens too late
- it is hard to compare low-level motion between nearby frames
- subtle motion cues may already be lost in late features
Early fusion
Another idea is to fuse temporal information immediately.
We reshape the input clip from $$ T \times 3 \times H \times W $$ into $$ 3T \times H \times W $$ and then use a standard 2D CNN.
So the first 2D convolution sees all frames together and mixes temporal information right away.
Intuition:
- compare frames with the very first convolution layer
- after that, the rest of the network is a normal 2D CNN
Problem:
- after the first layer, temporal information is already collapsed
- one layer of temporal processing may not be enough
3D CNN
The more natural solution is to use 3D convolution and 3D pooling.
Now every layer has shape $$ D \times T \times H \times W $$ and filters slide not only in space, but also in time.
A 2D convolution filter has shape roughly $$ C_{out} \times C_{in} \times K_h \times K_w $$ while a 3D convolution filter has shape $$ C_{out} \times C_{in} \times K_t \times K_h \times K_w. $$
This means that 3D CNNs slowly fuse information over the course of the network.
So we can compare three strategies:
- late fusion: build slowly in space, fuse all-at-once in time at the end
- early fusion: build slowly in space, fuse all-at-once in time at the start
- 3D CNN / slow fusion: build slowly in both space and time
Why 3D convolution is better than early fusion
Suppose the clip length is $T=16$.
In early fusion, the first 2D convolution uses a filter that spans all $16$ frames at once. So temporal information is mixed with a filter of temporal size $16$ immediately.
Problem:
- there is no temporal shift-invariance
- the model may need separate filters for the same motion happening at different moments in the clip
In 3D CNN, we instead use a local temporal kernel such as $3 \times 3 \times 3$. The filter slides across time.
This gives:
- local temporal modeling
- temporal shift-invariance
- better parameter sharing for motion patterns
The understanding of 3D CNN:
- 2D CNN is good for spatial patterns
- 3D CNN extends this idea so that motion patterns are also detected by sliding filters
- it is the direct CNN analogue of “local spatio-temporal pattern extraction”
C3D
A representative early 3D CNN is C3D.
Its style is very similar to VGG:
- almost all convolutions are $3 \times 3 \times 3$
- most pooling layers are $2 \times 2 \times 2$
- it became a classic pretrained video feature extractor
But 3D convolution is expensive. A $3 \times 3 \times 3$ conv is significantly more costly than a $3 \times 3$ conv.
So 3D CNNs usually improve temporal modeling, but they increase computation a lot.
Motion as a separate signal
Humans can often recognize actions from motion alone. This suggests that appearance and motion should sometimes be modeled separately.
Optical flow
A standard handcrafted motion representation is optical flow.
It estimates a displacement field between adjacent frames: $$ F(x,y) = (dx,dy) $$ meaning that the pixel at $(x,y)$ in frame $t$ moves to roughly $(x+dx, y+dy)$ in frame $t+1$.
So optical flow explicitly measures local motion. It usually has two channels:
- horizontal flow $dx$
- vertical flow $dy$
Two-stream networks
A classic action-recognition idea is to use two networks:
- Spatial stream
- input: RGB image / frames
- focuses on appearance
- Temporal stream
- input: stacked optical flow
- focuses on motion
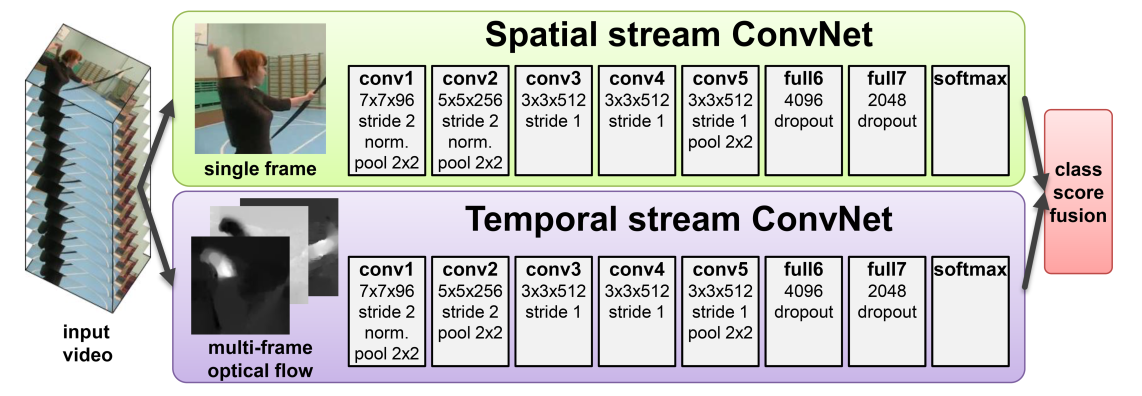
Then fuse the two predictions.
The understanding of two-stream networks:
- RGB tells us what things look like
- optical flow tells us how things move
- action recognition often needs both
A very interesting empirical fact is that the motion stream can be extremely strong, sometimes even stronger than the appearance stream.
Modeling longer temporal structure
So far, CNN-based temporal models mostly focus on short clips and local motion. But many actions have long-term structure:
- first event happens
- later another event happens
- the whole action depends on their order
CNN + RNN / LSTM
A natural idea is:
- first extract local features with a CNN (2D or 3D)
- then feed the sequence of features into an RNN / LSTM
This allows:
- many-to-one prediction: one output for the whole video
- many-to-many prediction: one output per frame / timestep
The understanding of CNN + RNN:
- CNN handles local spatial or short-term spatio-temporal structure
- RNN handles longer sequential dependency
But RNNs are hard to parallelize and are slow for long sequences.
Recurrent convolutional network
Another idea is to make recurrence happen directly on feature maps.
Instead of recurrently updating vectors, we recurrently update tensors of shape $$ C \times H \times W. $$
At layer $L$ and timestep $t$, the feature depends on two things:
- previous layer, same timestep
- same layer, previous timestep
This is like replacing the matrix multiplications in a vanilla RNN with 2D convolutions.
So recurrent convolutional networks combine:
- CNN’s spatial structure
- RNN’s theoretically infinite temporal extent
But they still inherit the sequential drawback of RNNs.
Self-attention for videos
Since self-attention is highly parallelizable, we can also apply it to video features.
Spatio-temporal self-attention / nonlocal block
Suppose a 3D CNN gives a feature map $$ C \times T \times H \times W. $$
A nonlocal block does the following:
- use $1 \times 1 \times 1$ conv to produce queries
- use $1 \times 1 \times 1$ conv to produce keys
- use $1 \times 1 \times 1$ conv to produce values
- flatten space-time locations into $THW$ tokens
- compute attention weights over all pairs of locations
- aggregate values using attention
- project back and add a residual connection
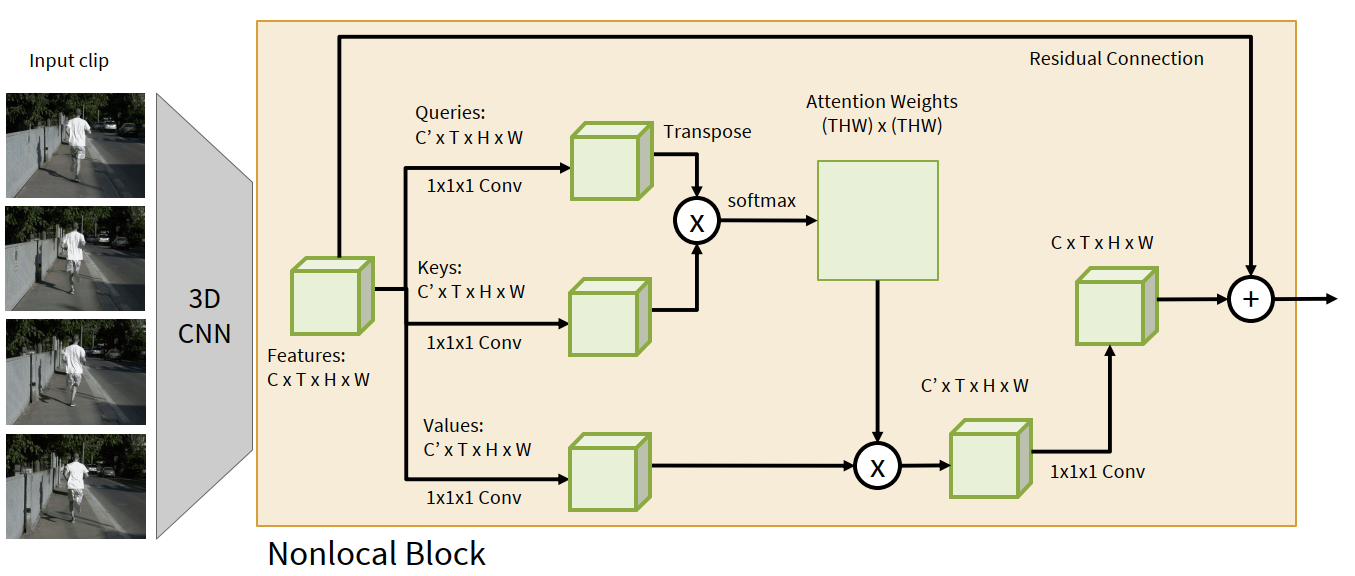
So every location can directly interact with every other location across both space and time.
High-level idea: 3D convolution is local in space-time, but self-attention can be global in space-time.
This nonlocal block can simply be inserted into an existing 3D CNN.
I3D: Inflating 2D networks to 3D
A very influential idea is I3D.
Instead of inventing a totally new architecture, we start from a successful 2D CNN and “inflate” it into 3D:
- replace each 2D conv / pool by a 3D version
- reuse the same architecture design for video
Even better, we can initialize a 3D kernel from a 2D kernel:
- copy the 2D kernel along the temporal dimension $K_t$ times
- divide by $K_t$
If the input video is constant across time, this initialization gives the same response as the original 2D conv.
Why this is useful:
- image architectures are already well studied
- ImageNet pretraining is valuable
- reusing 2D weights helps optimization on video tasks
So I3D is an elegant example of transferring image knowledge to video modeling.
Video Transformers
More recent video models often use Transformers. Typical ideas include:
- factorized attention over space / time
- pooling to reduce the number of tokens
- masked autoencoder style pretraining
The broad trend is clear:
- old video models: per-frame CNN, CNN+LSTM, two-stream CNN, 3D CNN
- modern video models: stronger spatio-temporal attention / video transformers / large-scale pretraining
Beyond short-clip classification
Video understanding is not only “classify one short clip”.
Two important extensions:
- Temporal action localization: given a long untrimmed video, identify when different actions happen
- Spatio-temporal detection: detect people / objects in both space and time, and classify their activities
So the video analogue of 2D detection is often to localize events along time, or even along both space and time.
Multimodal video understanding
Video is not just vision. It often also contains audio.
This opens many new tasks:
- multisensory fusion
- visually guided audio source separation
- audio-visual activity recognition
- egocentric multimodal video understanding
A key intuition is that vision and audio are often complementary:
- video can show who / what is producing the sound
- audio can preview where interesting moments happen
- combining both can improve understanding and efficiency
This is also one reason why modern video research is strongly connected to multimodal learning.
Efficient video understanding and video + LLMs
Because videos are long and expensive, efficiency is a core issue.
Typical directions:
- sample only salient clips
- adaptively choose modalities / computation
- design lightweight mobile video networks
Another strong trend is to combine video understanding with LLMs / multimodal foundation models.
The idea is to map videos into token-like representations and let large multimodal models answer questions, describe events, or reason over long video context.
So the overall historical picture is roughly:
- start from frame-based CNN baselines
- move to 3D CNNs and motion modeling
- add recurrence or attention for long-term structure
- move toward multimodal and foundation-model based video understanding
Glossary
- clip n. a short continuous segment of a video
- fps n. frames per second
- optical flow n. a displacement field describing pixel motion between adjacent frames
- temporal adj. related to time
- spatio-temporal adj. involving both space and time
- shift-invariant adj. giving similar responses when a pattern appears at different positions / times
- nonlocal adj. allowing interaction beyond a local neighborhood
- inflate v. expand a 2D operator / architecture into a 3D one
- multimodal adj. involving more than one modality, such as vision and audio